Braintrust Weekly Update
Ankur Goyal · Founder
It’s been another busy week for us at Braintrust. It’s been exciting to see many users start to ship their LLM apps into production and evaluate them with Braintrust. Here’s some of the new features we shipped this week:
Prompt playground variable improvements

Managing and writing evaluation test cases is tedious because they are usually in a JSON format. This means manually editing JSON strings all the time. This week we improved the playground so you can easily create input variables and edit them for your prompts and test cases without needing to edit raw JSON. Everything is visualized and accessible through our UI. The input names also autofill when you are typing out the prompt.
Time duration summary metrics for experiments
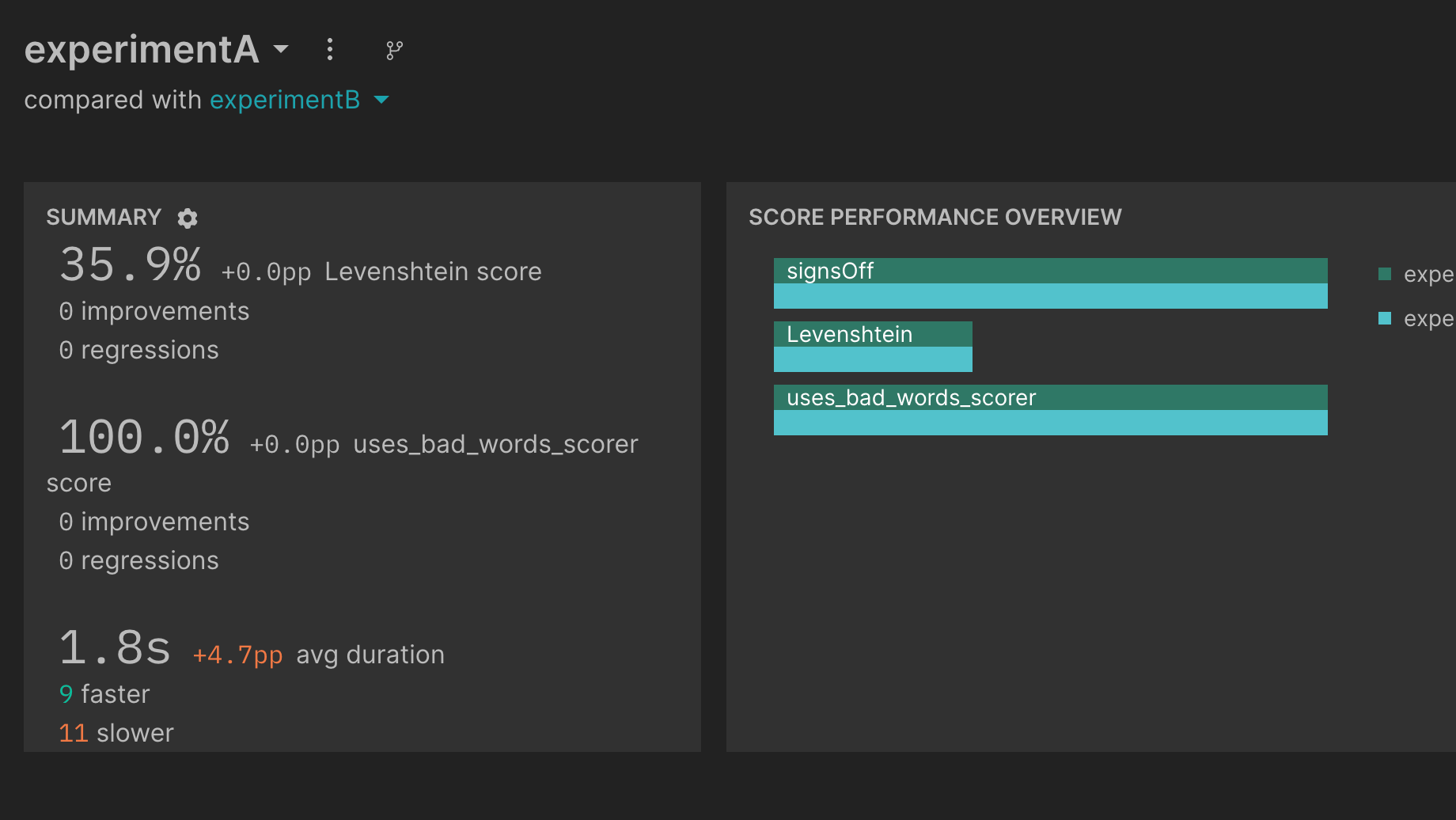
When iterating on LLM apps there is a tradeoff between time to execute and accuracy. For example, running more context retrievals can take longer but can improve the quality of the answer for a RAG app. We added in time duration metrics to Braintrust experiments so that you can compare how long each test case changes between experiments and compare it to overall accuracy.
Release notes:
- Improved prompt playground variable handling and visualization
- Added time duration statistics per row to experiment summaries
- Multiple performance optimizations and bug fixes
Fun links and mentions:
- Madrona wrote an excellent report on the GenAI development stack including Braintrust
- Ironclad updated their prompt engineering tool: Rivet launched plugins including a Braintrust plugin
- Ankur spoke on the Bits and Bots podcast with Parcha about AI agents in production
- We received our first community contribution to our autoevals library (our model graded evals library). Huge thank you to Edward Atkins @ecatkins for authoring the PR.
Braintrust is the enterprise-grade stack for building AI products. From evaluations, to prompt playground, to data management, we take uncertainty and tedium out of incorporating AI into your business.
Sign up now, or check out our pricing page for more details.