AI proxy
This guide walks through how to use the Braintrust AI proxy to access OpenAI's models, Anthropic models, LLaMa 2, Mistral, and others behind a single API. The AI proxy is a powerful tool that:
- Simplifies your code by providing a single API across AI providers.
- Reduces your costs by automatically caching results and reusing them when possible.
- Increases observability by automatically logging your requests. [Coming soon]
To read more about why we launched the AI proxy, check out our blog post announcing the feature.
The AI proxy is free for all users. You can access it without a Braintrust account, by simply using your API key from any of the supported providers. However, with a Braintrust account, you can use a single API key to access all services.
Quickstart
You can use your favorite OpenAI drivers, and simply set the base url to https://braintrustproxy.com/v1.
Try running the following script in your favorite language, twice.
import { OpenAI } from "openai";
const client = new OpenAI({
baseURL: "https://braintrustproxy.com/v1",
apiKey: process.env.OPENAI_API_KEY, // Can use Braintrust, Anthropic, etc. API keys here
});
async function main() {
const start = performance.now();
const response = await client.chat.completions.create({
model: "gpt-3.5-turbo", // Can use claude-2, llama-2-13b-chat, etc. here
messages: [{ role: "user", content: "What is a proxy?" }],
seed: 1, // A seed activates the proxy's cache
});
console.log(response.choices[0].message.content);
console.log(`Took ${(performance.now() - start) / 1000}s`);
}
main();If you have access to Perplexity or Anthropic, feel free to use their API keys with mistral-7b-instruct or
claude-instant-1.2 instead. Under the hood, we're proxying the requests through a Cloudflare worker, caching
the results with end-to-end encryption, and returning the results.
Key features
The proxy is a drop-in replacement for the OpenAI API, with a few killer features:
- Automatic caching of results, with configurable semantics
- Interopability with other providers, including a wide range of open source models
- API key management
Caching
The proxy automatically caches results, and reuses them when possible. Because the proxy runs on the edge, you can expect cached requests to be returned in under 100ms. This is especially useful when you're developing and frequently re-running or evaluating the same prompts many times.
The cache follows the following rules:
- There are three caching modes:
auto(default),always,never. - In
automode, requests are cached if they havetemperature=0or theseedparameter set. - In
alwaysmode, requests are cached as long as they are one of the supported paths (/chat/completions,/completions, or/embeddings) - In
nevermode, the cache is never read or written to.
You can set the cache by passing the x-bt-use-cache header to your request. For example, to always use the cache,
import { OpenAI } from "openai";
const client = new OpenAI({
baseURL: "https://braintrustproxy.com/v1",
defaultHeaders: {
"x-bt-use-cache": "always",
},
apiKey: process.env.OPENAI_API_KEY, // Can use Braintrust, Anthropic, etc. API keys here
});
async function main() {
const response = await client.chat.completions.create({
model: "gpt-3.5-turbo", // Can use claude-2, llama-2-13b-chat, etc. here
messages: [{ role: "user", content: "What is a proxy?" }],
});
console.log(response.choices[0].message.content);
}
main();Encryption
We use AES-GCM to encrypt the cache, using a key derived from your API key. Currently, results are cached for 1 week.
This design ensures that the cache is only accessible to you, and that we cannot see your data. We also do not store or log API keys.
Because the cache's encryption key is your API key, cached results are scoped to an individual user. However, Braintrust customers can opt-into sharing cached results across users within their organization.
Supported models
The full list of supported models is
- gpt-3.5-turbo (openai, azure)
- gpt-35-turbo (azure)
- gpt-3.5-turbo-0125 (openai, azure)
- gpt-3.5-turbo-1106 (openai, azure)
- gpt-3.5-turbo-16k (openai, azure)
- gpt-35-turbo-16k (azure)
- gpt-4 (openai, azure)
- gpt-4-32k (openai, azure)
- gpt-4-vision-preview (openai, azure)
- gpt-4-1106-vision-preview (openai, azure)
- gpt-4-turbo (openai, azure)
- gpt-4-turbo-2024-04-09 (openai, azure)
- gpt-4-turbo-preview (openai, azure)
- gpt-4-0125-preview (openai, azure)
- gpt-4-1106-preview (openai, azure)
- gpt-3.5-turbo-0613 (openai, azure)
- gpt-3.5-turbo-16k-0613 (openai, azure)
- gpt-3.5-turbo-0301 (openai, azure)
- gpt-4-0613 (openai, azure)
- gpt-4-32k-0613 (openai, azure)
- gpt-4-0314 (openai, azure)
- gpt-4-32k-0314 (openai, azure)
- gpt-3.5-turbo-instruct (openai, azure)
- gpt-3.5-turbo-instruct-0914 (openai, azure)
- text-davinci-003 (openai, azure)
- claude-2 (anthropic)
- claude-instant-1 (anthropic)
- claude-2.0 (anthropic)
- claude-2.1 (anthropic)
- claude-instant-1.2 (anthropic)
- claude-3-opus-20240229 (anthropic)
- claude-3-sonnet-20240229 (anthropic)
- claude-3-haiku-20240307 (anthropic)
- anthropic.claude-3-opus-20240229-v1:0 (bedrock)
- anthropic.claude-3-haiku-20240307-v1:0 (bedrock)
- anthropic.claude-3-sonnet-20240229-v1:0 (bedrock)
- meta/llama-2-70b-chat (replicate)
- llama-2-70b-chat (perplexity)
- llama-2-13b-chat (perplexity)
- llama3-8b-8192 (groq)
- llama3-70b-8192 (groq)
- llama2-70b-4096 (groq)
- codellama-34b-instruct (perplexity)
- mistral-7b-instruct (perplexity)
- mixtral-8x7b-instruct (perplexity)
- mixtral-8x22b-instruct (perplexity)
- mixtral-8x7b-32768 (groq)
- gemma-7b-it (groq)
- mistralai/Mistral-7B-Instruct-v0.1 (together)
- mistralai/mixtral-8x7b-32kseqlen (together)
- mistralai/Mixtral-8x7B-Instruct-v0.1 (together)
- mistralai/Mixtral-8x22B (together)
- mistralai/Mixtral-8x22B-Instruct-v0.1 (together)
- meta-llama/Llama-2-70b-chat-hf (together)
- meta-llama/Meta-Llama-3-70B (together)
- meta-llama/Llama-3-70b-chat-hf (together)
- meta-llama/Llama-3-8b-hf (together)
- meta-llama/Llama-3-8b-chat-hf (together)
- NousResearch/Nous-Hermes-2-Yi-34B (together)
- deepseek-ai/deepseek-coder-33b-instruct (together)
- llama-3-8b-instruct (perplexity)
- llama-3-70b-instruct (perplexity)
- codellama-70b-instruct (perplexity)
- mistral (ollama)
- mistral-tiny (mistral)
- mistral-small (mistral)
- mistral-medium (mistral)
- openhermes-2-mistral-7b (perplexity)
- openhermes-2.5-mistral-7b (perplexity)
- pplx-7b-chat (perplexity)
- pplx-70b-chat (perplexity)
- pplx-7b-online (perplexity)
- pplx-70b-online (perplexity)
- phi (ollama)
- gemini-pro (google)
We are constantly adding new models, and if you have a model you'd like to see supported, please let us know!
API key management
The proxy allows you to either use the provider's API key, or your Braintrust API key. If you use the provider's API key, you can use the proxy without a Braintrust account, and caching will still work (scoped to your API key).
However, you can manage all your API keys in one place by configuring secrets in your Braintrust account. To do so, sign up for an account and add each provider's API key on the secrets page.
Custom models
If you have custom models as part of your OpenAI or other accounts, you can use them with the proxy by adding
them to an endpoint. For example, if you have a custom model called gpt-3.5-acme, you can add it to an endpoint
like so:
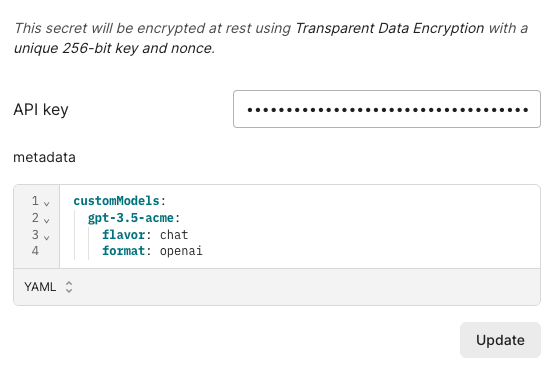
Each custom model must have a flavor (chat or completion) and format (openai, anthropic, or google).
Specifying an org
If you are part of multiple organizations, you can specify which organization to use by passing the x-bt-org-name
header in the SDK:
import { OpenAI } from "openai";
const client = new OpenAI({
baseURL: "https://braintrustproxy.com/v1",
defaultHeaders: {
"x-bt-org-name": "Acme Inc",
},
apiKey: process.env.OPENAI_API_KEY, // Can use Braintrust, Anthropic, etc. API keys here
});
async function main() {
const response = await client.chat.completions.create({
model: "gpt-3.5-turbo", // Can use claude-2, llama-2-13b-chat, etc. here
messages: [{ role: "user", content: "What is a proxy?" }],
});
console.log(response.choices[0].message.content);
}
main();Load balancing
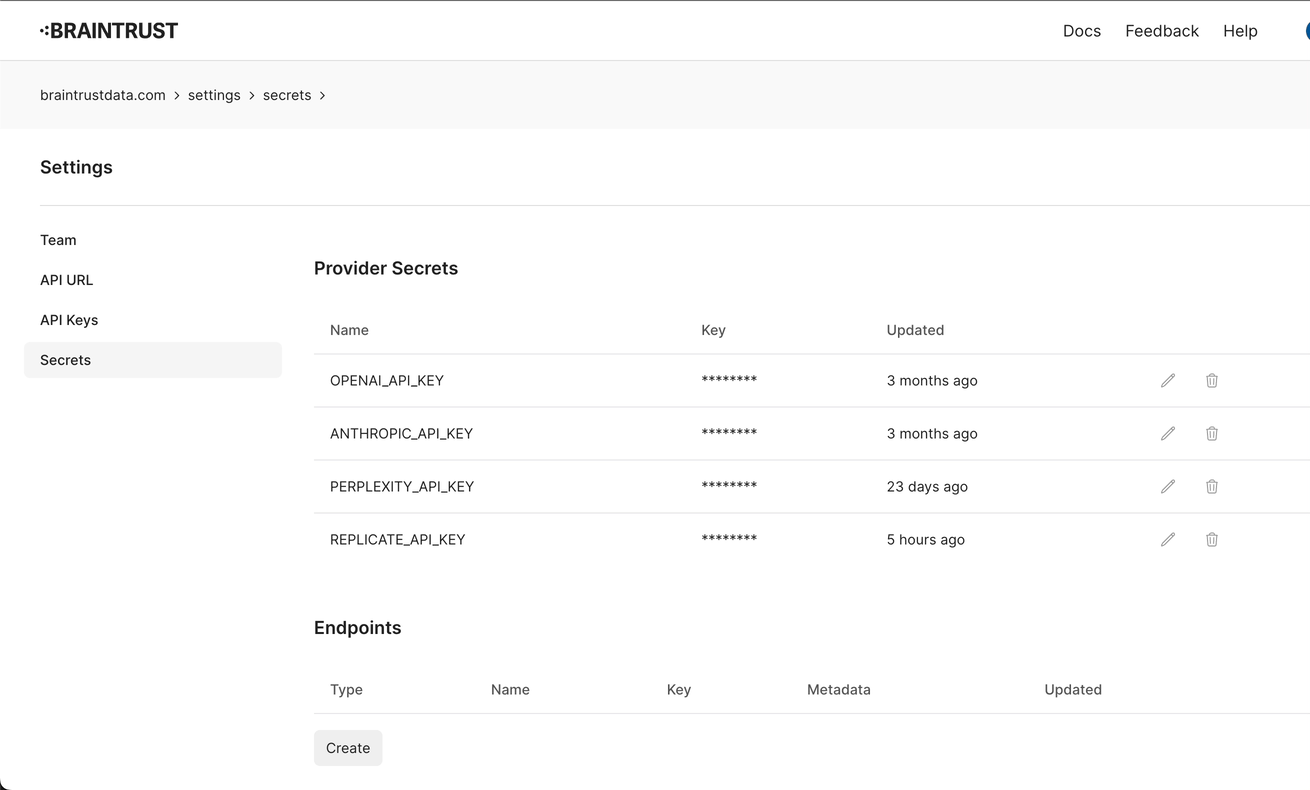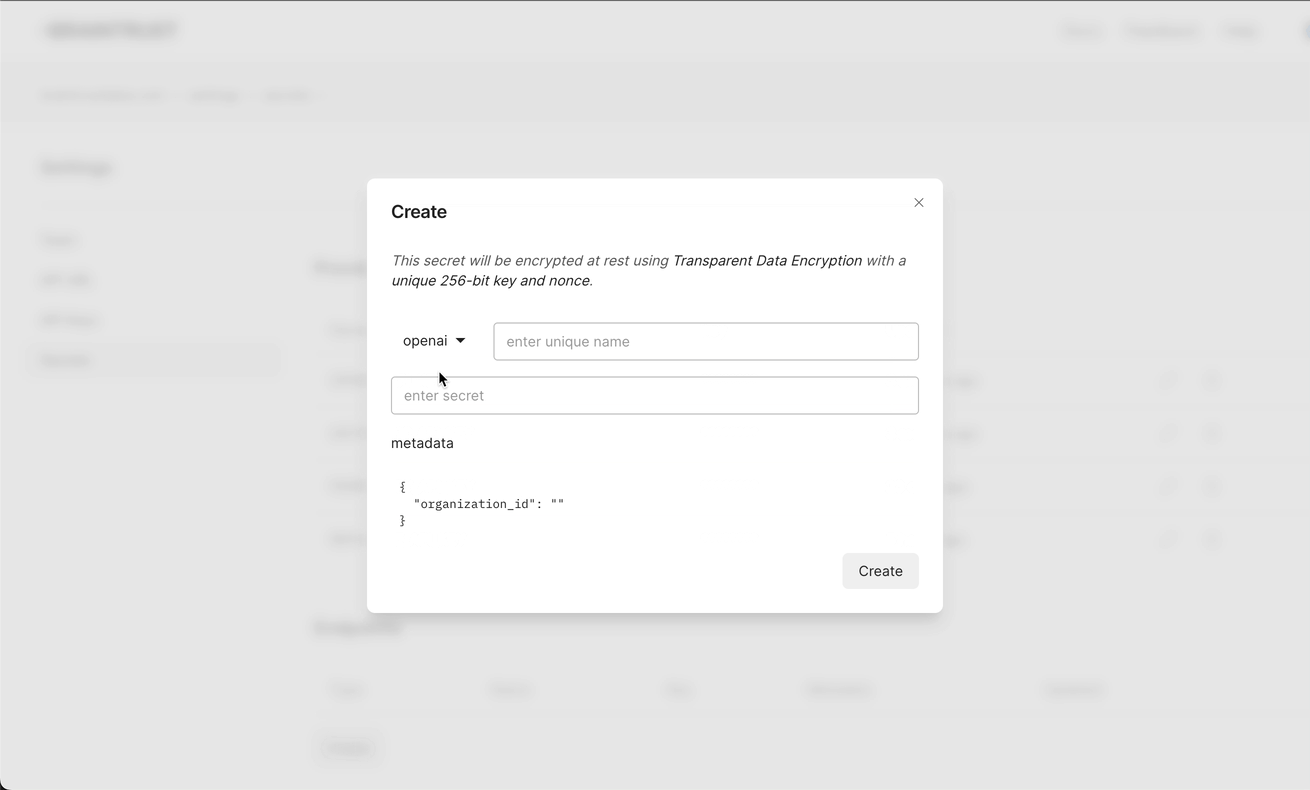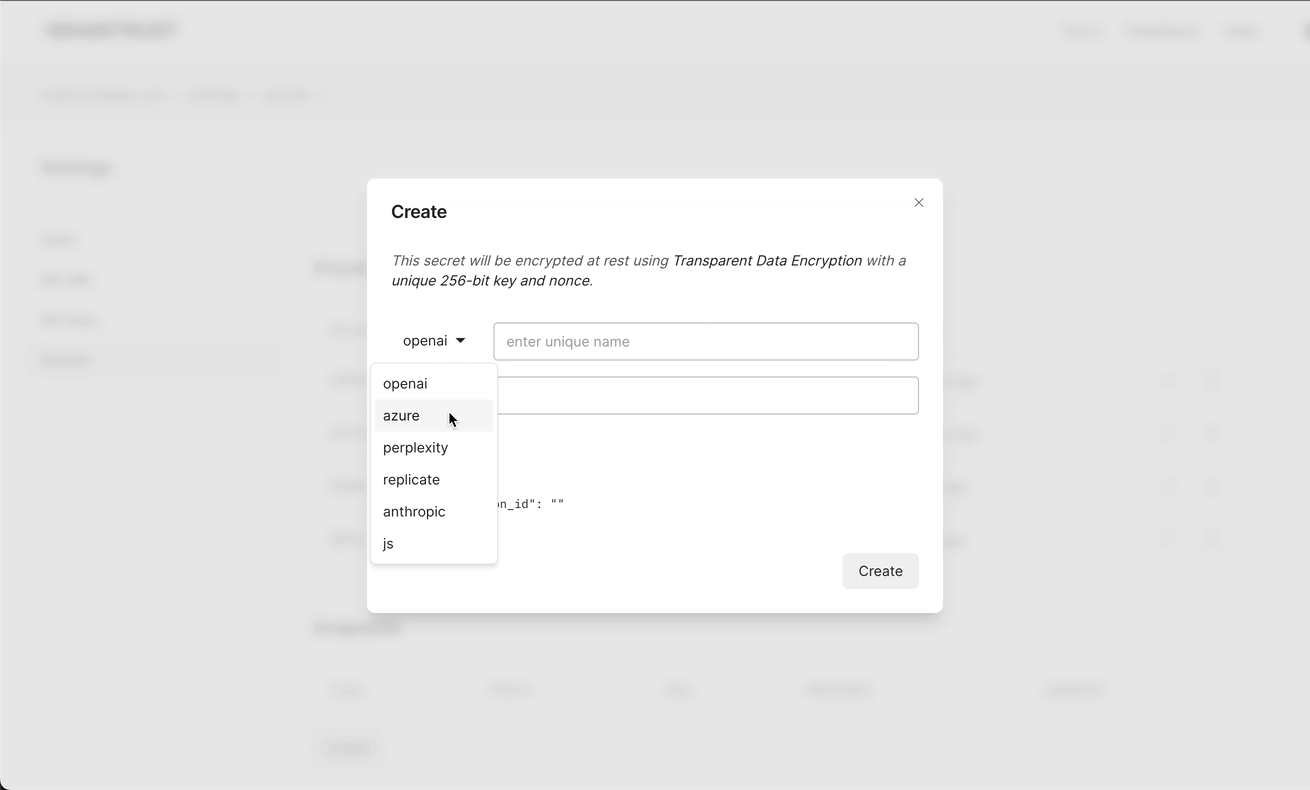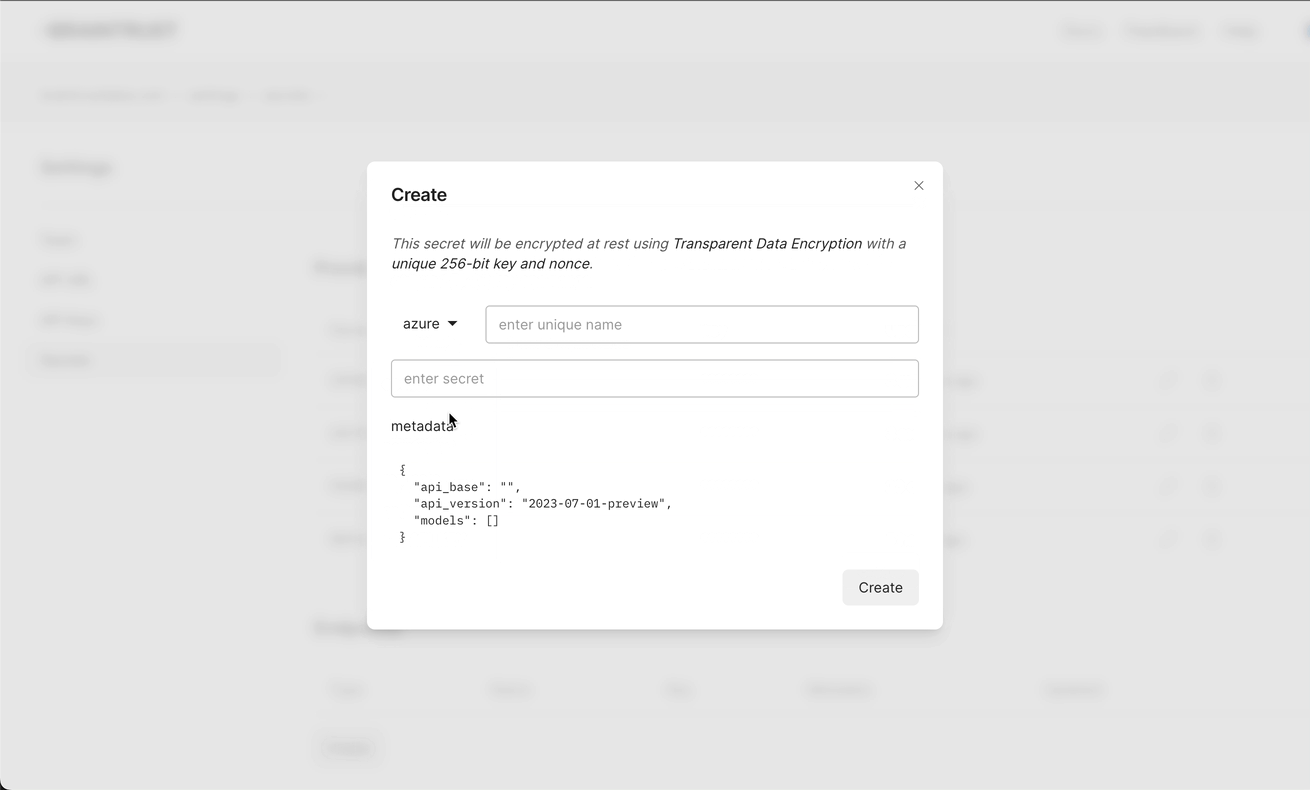
If you have multiple API keys for a given model type, e.g. OpenAI and Azure for gpt-3.5-turbo, the proxy will
automatically load balance across them. This is a useful way to work around per-account rate limits and provide
resiliency in case one provider is down.
You can setup endpoints directly on the secrets page in your Braintrust account by adding endpoints:
Advanced configuration
The following headers allow you to configure the proxy's behavior:
x-bt-use-cache:auto | always | never. See Cachingx-bt-use-creds-cache:auto | always | never. Similar tox-bt-use-cache, but controls whether to cache the credentials used to access the provider's API. This is useful if you are rapidly tweaking credentials and don't want to wait ~60 seconds for the credentials cache to expire.x-bt-org-name: Specify if you are part of multiple organizations and want to use API keys/log to a specific org.x-bt-endpoint-name: Specify to use a particular endpoint (by its name).
Open source
The AI proxy is open source, and you can find the code on Github.